Why This Project Exists
RetailOS Lite was built for a rapid internship assessment: design and ship a mini AI-native retail execution workflow in 72 hours. The mandatory scope sounded simple on paper: store visits, shelf image upload, AI shelf analysis, supervisor summary, dashboard, and at least one fraud signal. The real challenge was making those pieces feel like a believable operational system instead of a stitched-together demo.
I treated the assignment as a systems problem. The rep flow had to stay fast even when AI was slow. Fraud had to be explainable. Outlet creation had to survive messy shop names in a dense Bangladesh retail environment. RAG had to answer list questions from exact data rather than vibes. Observability had to explain why a visit was stuck. The result was a compact but production-shaped platform with clear service boundaries, async processing, and operational recovery paths.
My Role
I worked across the backend, AI pipeline, worker architecture, fraud detection, RAG assistant, observability, deployment, and production hardening. The frontend was collaborative, but my main contribution was turning the product brief into a system that could be debugged, extended, and defended in front of senior engineers.
Architecture
Split the system into Next.js APIs, a BullMQ worker, a FastAPI AI service, Postgres, Redis, object storage, and observability services.
AI Pipeline
Separated YOLO detection, OpenAI visual reasoning, deterministic scoring, report generation, and vector indexing into explicit stages.
Operational Hardening
Added DLQs, admin replay, rate limits, API-key service auth, pre-signed uploads, actor-aware EventLog records, and Dockerized local infrastructure.
System Architecture
The most important design decision was to keep the request path thin. Next.js owns user-facing workflows and orchestration, but all expensive or failure-prone work runs in a worker or AI service. That keeps rep submissions responsive and makes every heavy stage observable.
flowchart TB
Rep[Rep PWA] --> Web[Next.js App Router]
Sup[Supervisor Console] --> Web
Web --> Auth[Auth.js + RBAC]
Web --> DB[(PostgreSQL + Prisma)]
Web --> Obj[MinIO / S3-compatible storage]
Web --> Redis[(Redis / BullMQ)]
Web --> EventLog[(EventLog)]
Redis --> Worker[Node BullMQ Worker]
Worker --> DB
Worker --> EventLog
Worker --> AI[FastAPI AI Service]
Worker --> WhatsApp[Twilio WhatsApp Alerts]
AI --> YOLO[YOLO Shelf Detection]
AI --> Vision[OpenAI POSM + Summary]
AI --> Score[Deterministic Compliance Engine]
AI --> Pinecone[(Pinecone)]
YOLO -. optional .-> Modal[Modal GPU]
Web --> Assistant[RAG Assistant API]
Assistant --> DB
Assistant --> AI
Web --> Sentry[Sentry]
Worker --> Sentry
AI --> Sentry
Worker --> Prom[Prometheus]
AI --> Prom
Web --> Prom
Prom --> Grafana[Grafana / Loki / Tempo]
Core Workflow
The workflow is intentionally shaped like a real field execution product: a rep can work under unreliable network conditions, the worker does the expensive analysis, and the supervisor sees an inspectable decision trail rather than a magic AI label.
- Rep creates a visit: outlet name/search, GPS, timestamp, notes, and one shelf image.
- Upload is stored: local storage for dev or pre-signed MinIO/S3 upload for production-shaped demos.
- Visit is queued: Next.js returns quickly with
ANALYZING; BullMQ owns retries and backoff. - Worker runs fraud checks: duplicate hash, perceptual hash, GPS mismatch, timestamp anomaly, and EXIF GPS/time checks.
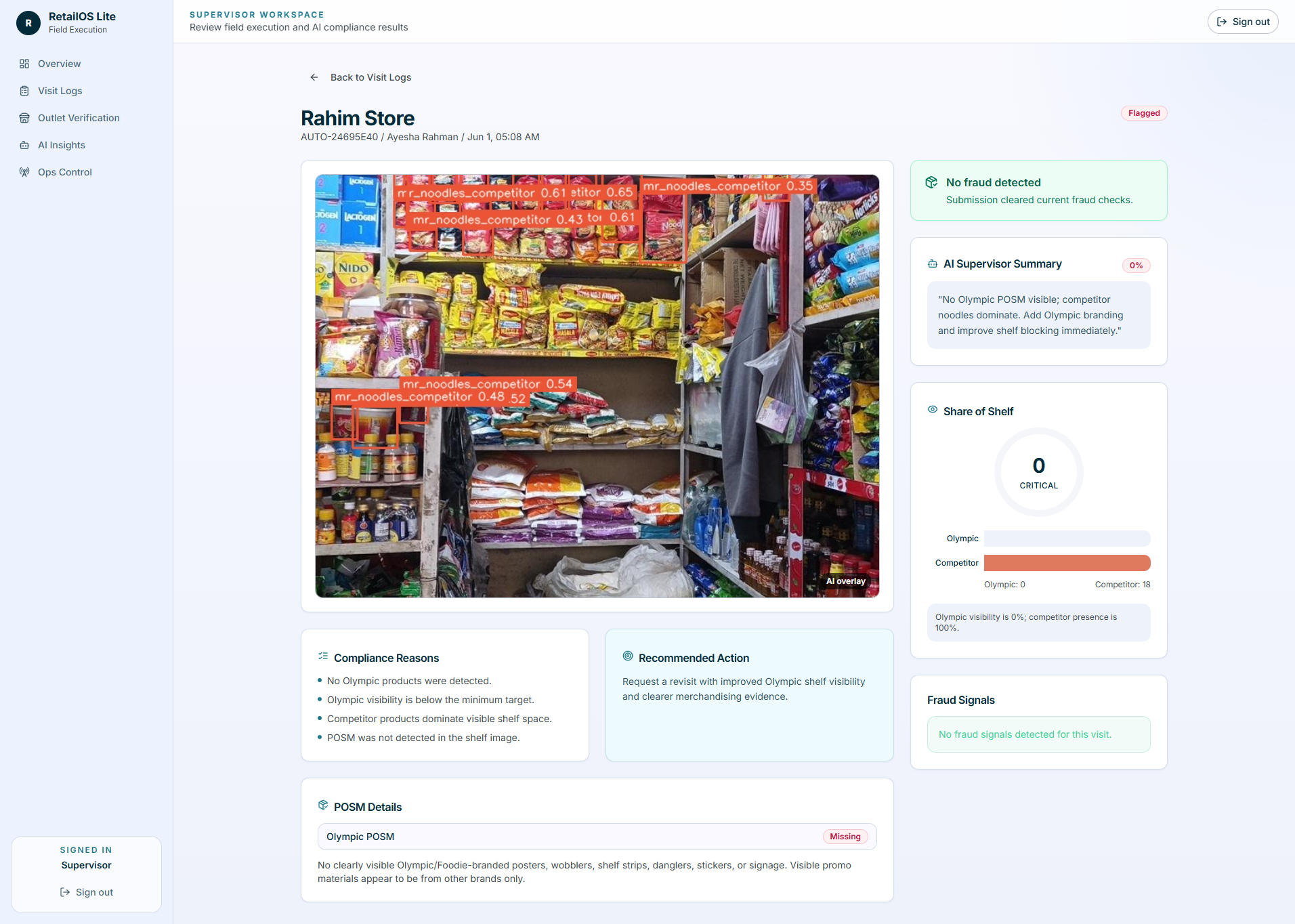
- AI service analyzes shelf evidence: YOLO detects Olympic Foodie Noodles and competitor products; OpenAI audits POSM and shelf quality.
- Compliance is scored: deterministic rules produce score, status, reasons, and recommended action.
- Report is indexed: the worker writes a RAG-ready VisitReport and queues embedding into Pinecone.
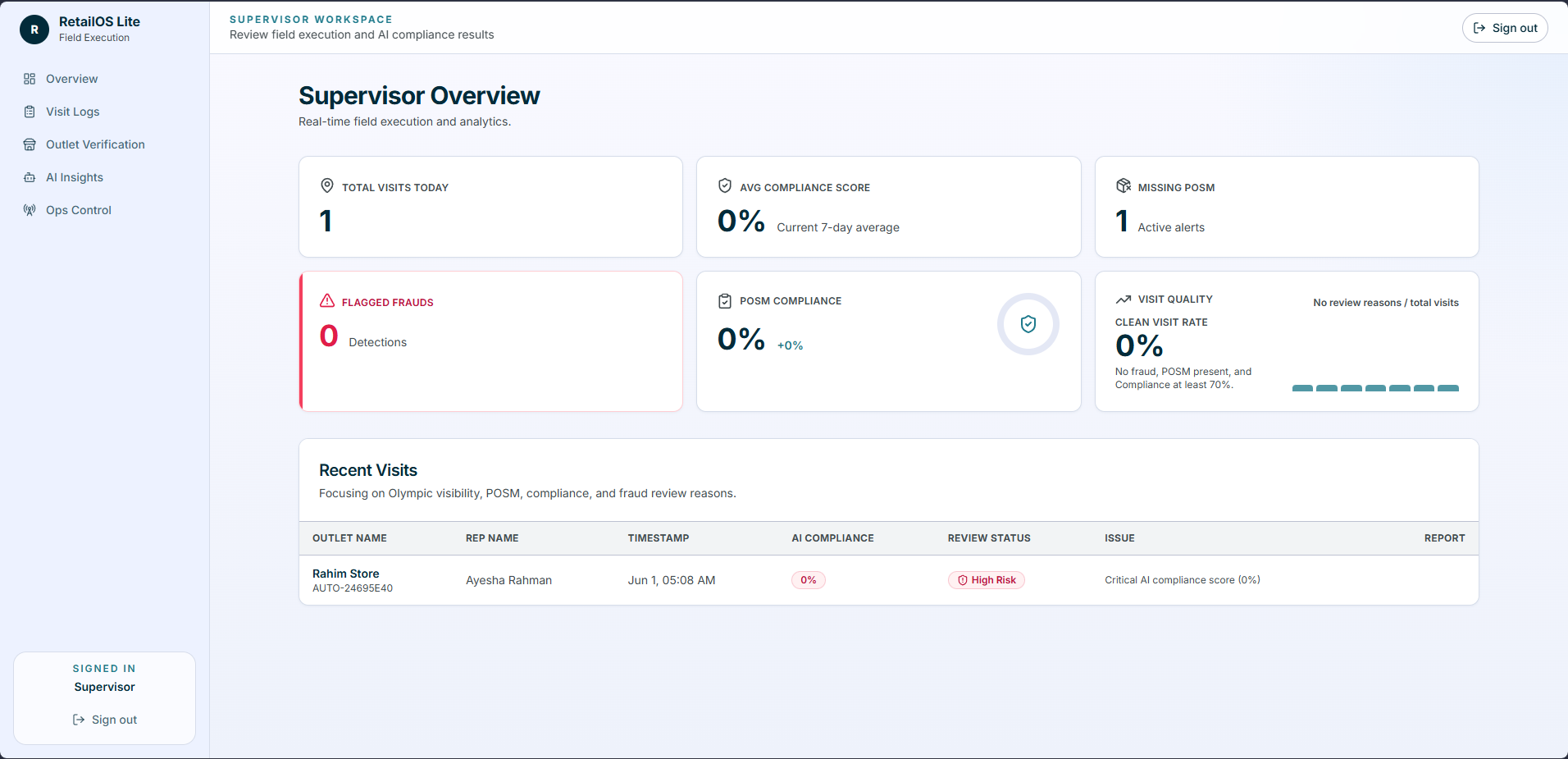
- Supervisor reviews: dashboard, visit logs, outlet verification, ops timelines, and assistant answers all read from persisted state.
Product Walkthrough
The screenshots below show the parts that matter most in a live evaluation: a fast rep workflow, inspectable AI reports, governed outlet creation, assistant-backed insights, and operational telemetry for the async pipeline.

Engineering Deep Dives
Problem: YOLO inference, OpenAI vision, fraud checks, report generation, and embedding can take seconds and occasionally fail. If that work runs inside a Next.js API request, the rep waits, serverless timeouts become likely, and retries become unsafe.
Implementation: visit submission enqueues an
analyze_visit BullMQ job and returns immediately. The worker owns the full
pipeline: fraud checks, AI service call, persistence, report generation, WhatsApp alerting,
and embedding enqueue. Jobs retry with exponential backoff and terminal failures are copied
into DLQs.
Why it matters: this turns AI analysis into durable operational work. A failed OpenAI call or weird image format does not strand the user. Admins can inspect DLQ payloads and replay jobs without asking the rep to revisit the store.
Problem: the YOLO model was trained for product and competitor detection, not POSM. OpenAI can reason about POSM and shelf quality, but it should not be trusted as a precise counter in dense shelf images.
Implementation: YOLO handles grounded detections: product count, competitor count, bounding boxes, overlay images, and share-of-shelf area. OpenAI handles untrained visual reasoning: Olympic/Foodie POSM, shelf neatness, competitor pressure, and supervisor summaries. The compliance score remains deterministic and inspectable.
Tradeoff: this gives a cleaner story than "we used AI everywhere." Each model has a job, and the final score is reproducible because rules, not LLM mood, decide the compliance band.
Problem: fraud in field execution is messy. A rep might reuse a photo, submit from the wrong place, delay sync, or upload an image with mismatched EXIF metadata. One aggressive detector would create false positives.
Implementation: the worker calculates five signals: exact SHA-256 duplicate, perceptual dHash duplicate, GPS mismatch, timestamp anomaly, and EXIF GPS/time mismatch. Missing EXIF is not treated as fraud because many phones or upload paths strip metadata.
Result: supervisors see a risk label plus concrete reasons. The system
avoids a black-box "fraud probability" and instead persists relational
FraudSignal rows that can be counted, audited, and queried by the assistant.
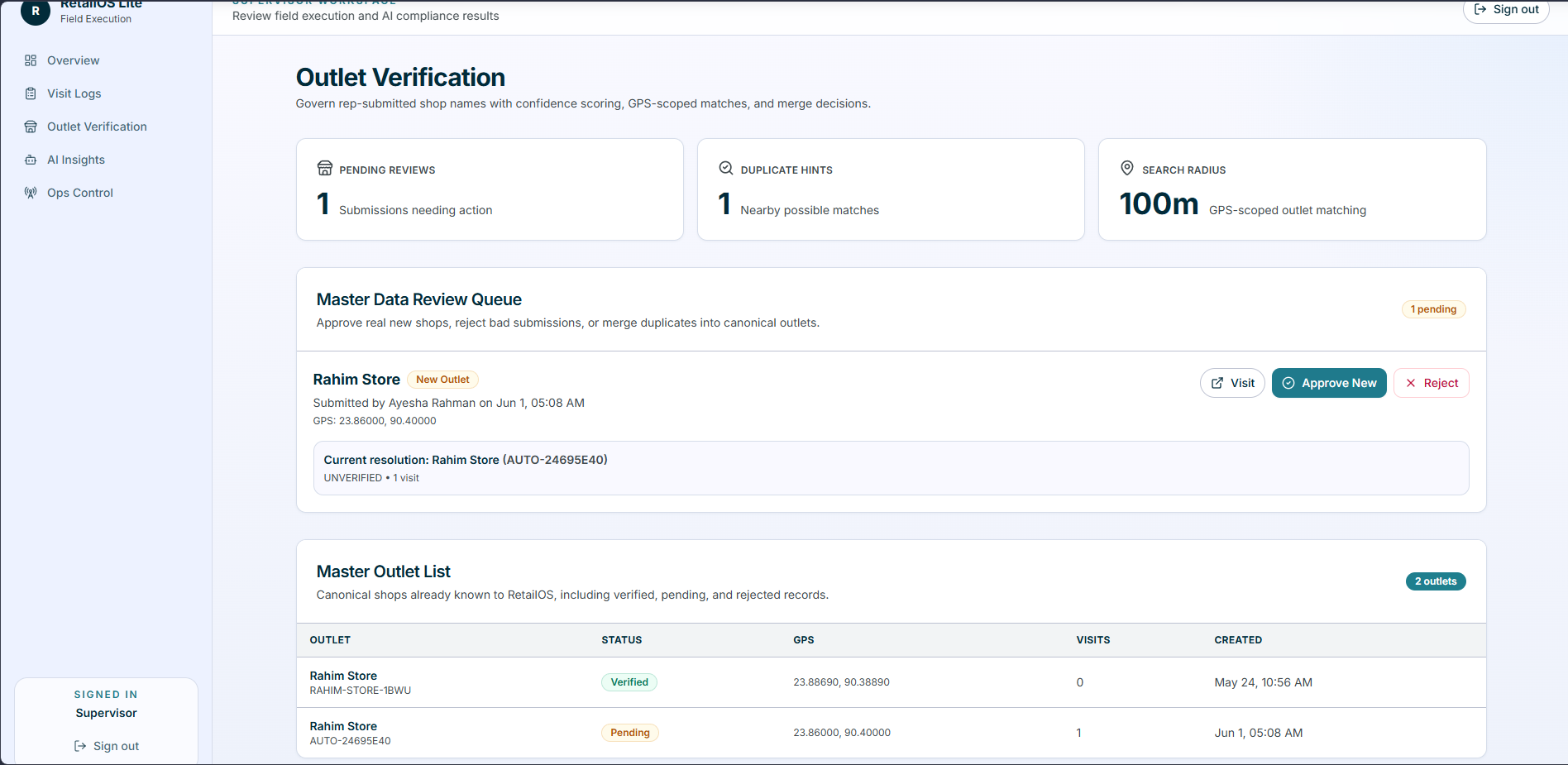
Problem: in small local shops, a dropdown of known outlets is brittle.
But if reps freely type names, the database fills with duplicates like
Maa Store, Maa store, and Maa Dokan.
Implementation: reps submit names and GPS quickly,
but they do not directly create verified canonical outlets. The system normalizes names,
uses pg_trgm plus bounded geo prefiltering, scores name and distance, creates
aliases, and routes ambiguous matches into a supervisor review queue.
Merge semantics: duplicate merge is non-destructive. Existing visits and reports are retargeted to the canonical outlet, source outlets are marked rejected, aliases are preserved, and affected Pinecone vectors are reindexed so the chatbot stays consistent.
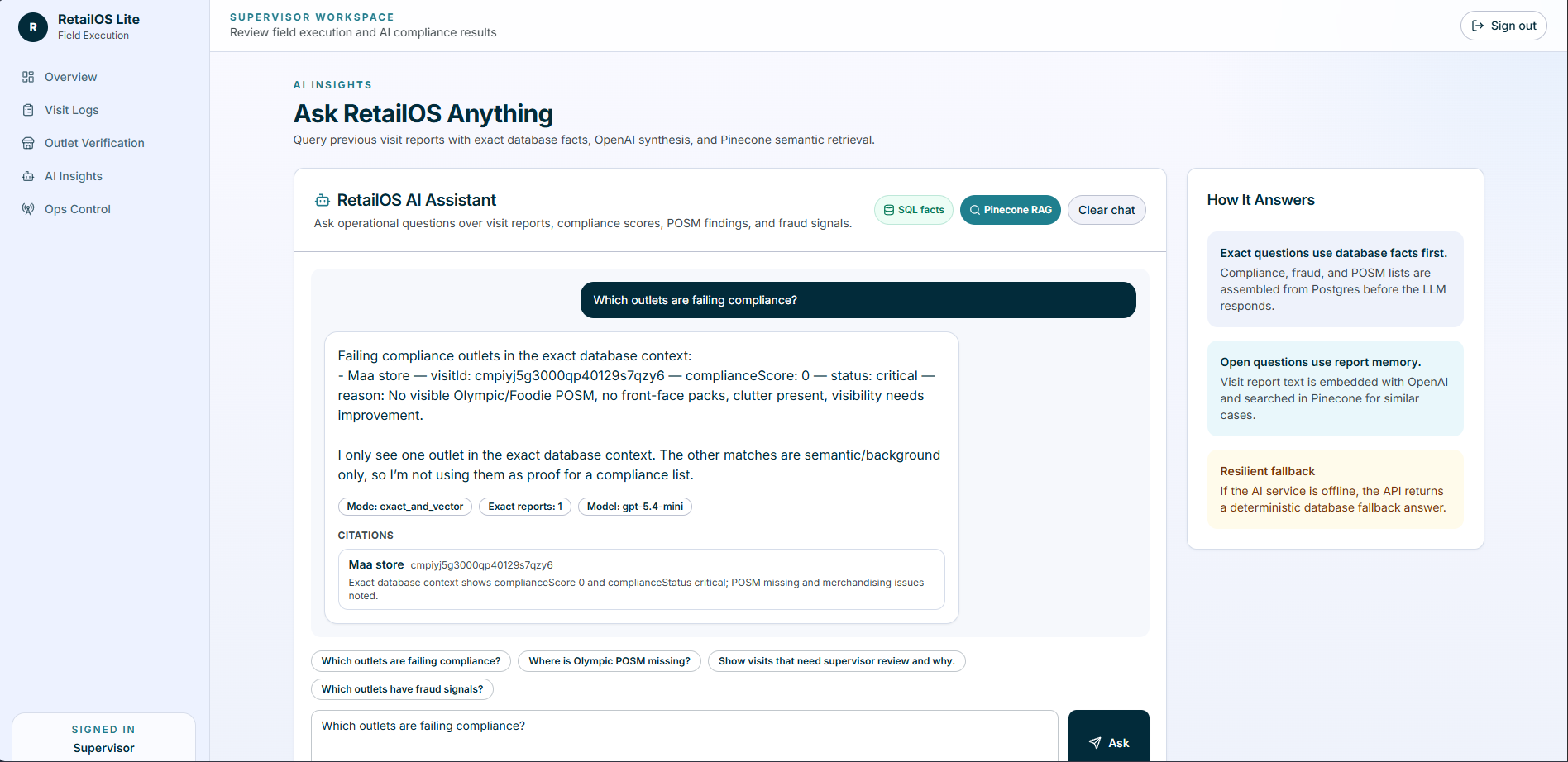
Problem: questions like "which outlets have fraud signals?" or "which outlets are failing compliance?" are exact operational queries. Vector search alone can retrieve semantically similar visits, but it cannot prove a list is complete.
Implementation: the assistant first builds exact
Prisma context from VisitReport, Visit, Outlet,
AIResult, and FraudSignal. Pinecone semantic retrieval is used
as supplemental context for trend and narrative questions. The LLM is instructed to prefer
exact context for list/count/fraud/POSM/compliance answers.
Result: the chatbot behaves like operational tooling, not a loose demo bot. It can cite visit IDs and outlet names and avoid marking an outlet fraudulent just because a semantic match looked related.
Problem: retail reps often work in shops where mobile connectivity is inconsistent. If the submission flow hard-depends on the network, the whole product fails in the exact environment it targets.
Implementation: visit drafts and image blobs are queued in IndexedDB. TanStack Query coordinates retry and sync when the browser comes back online. Client-generated IDs and idempotency keys prevent duplicated visits during retry.
Design detail: when offline, outlet resolution stores the submitted outlet candidate and lets the server resolve it during sync. That keeps the rep unblocked without pretending the client can do authoritative master-data matching offline.
Problem: async systems fail in boring but expensive ways: Redis backlog,
stuck workers, slow OpenAI calls, failed embeddings, or a visit sitting at
ANALYZING with no explanation.
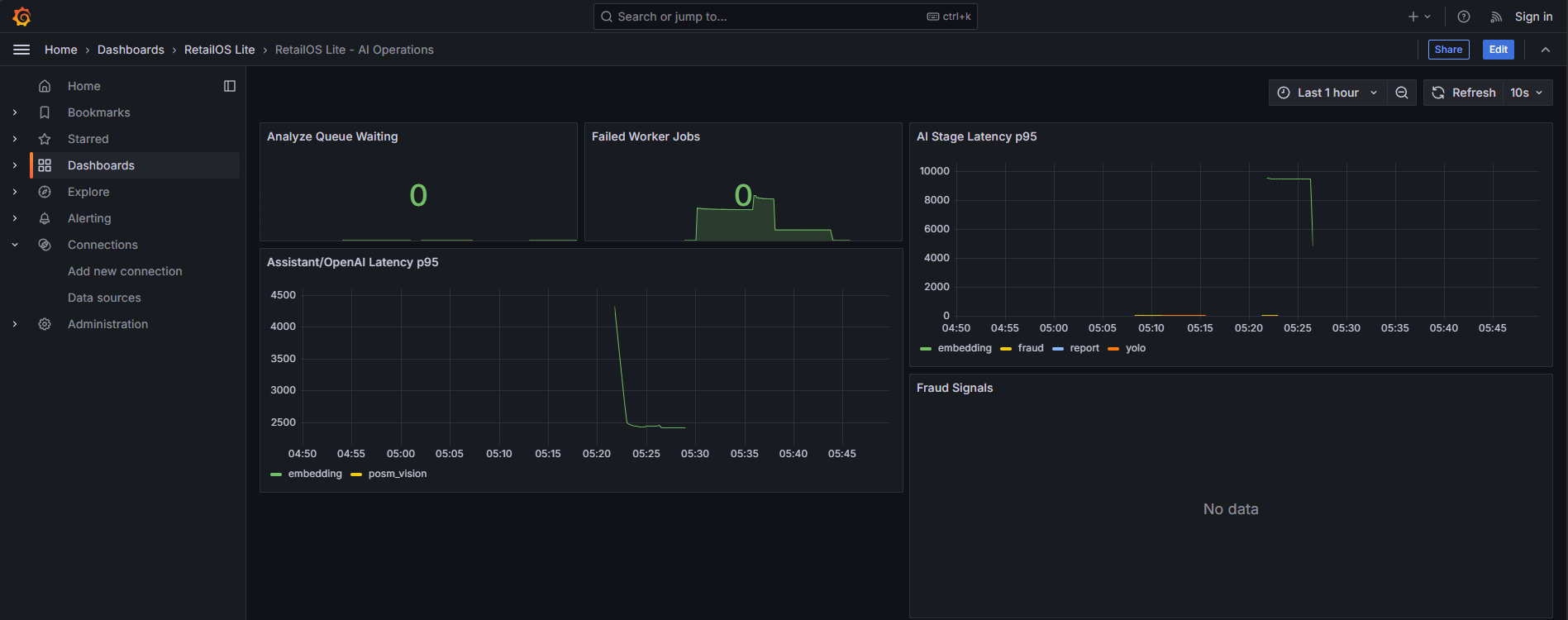
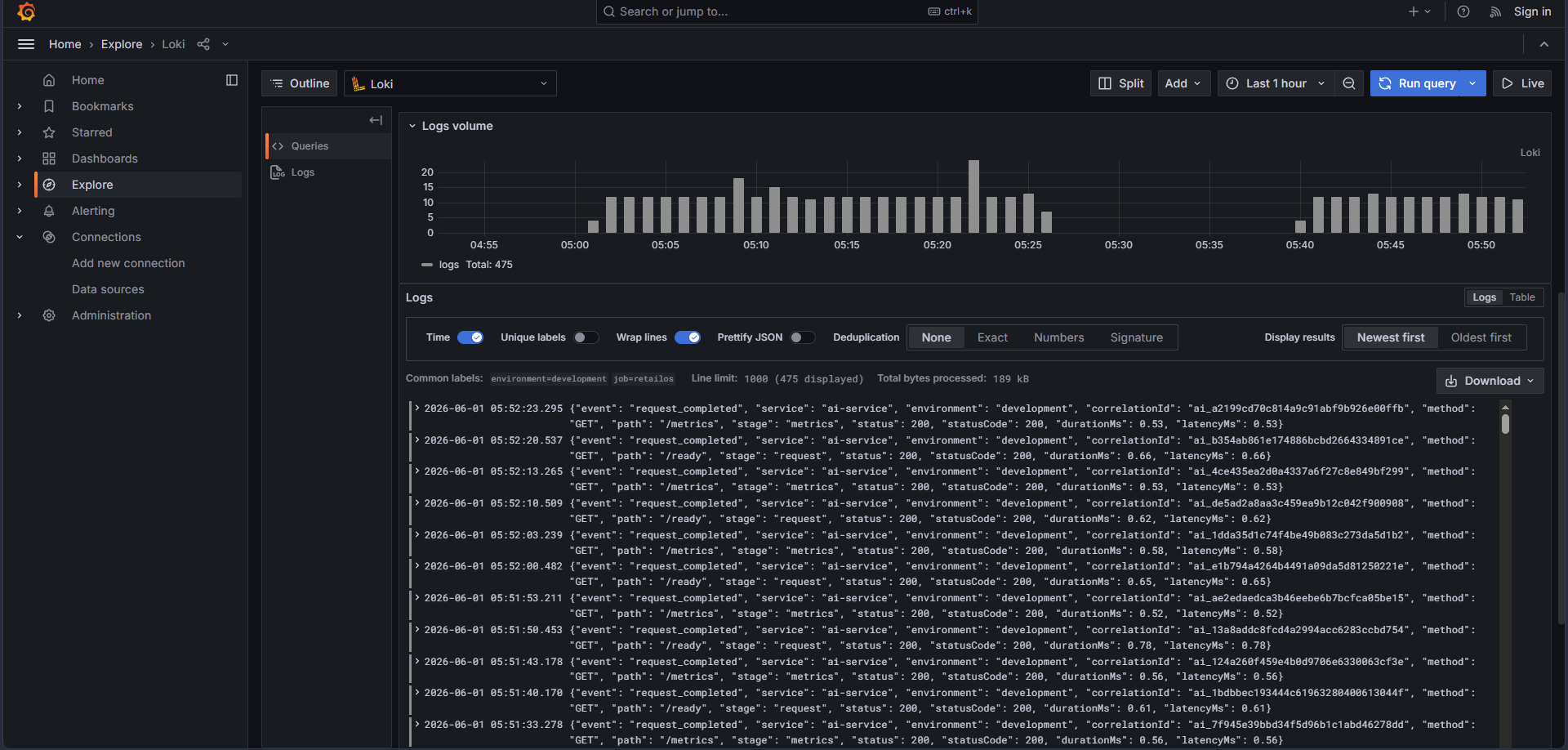
Implementation: I added four layers of telemetry:
product-native EventLog timelines, structured JSON logs, Prometheus metrics, and Sentry
error capture. Docker Compose brings up Grafana, Loki, Tempo, and Prometheus locally, but
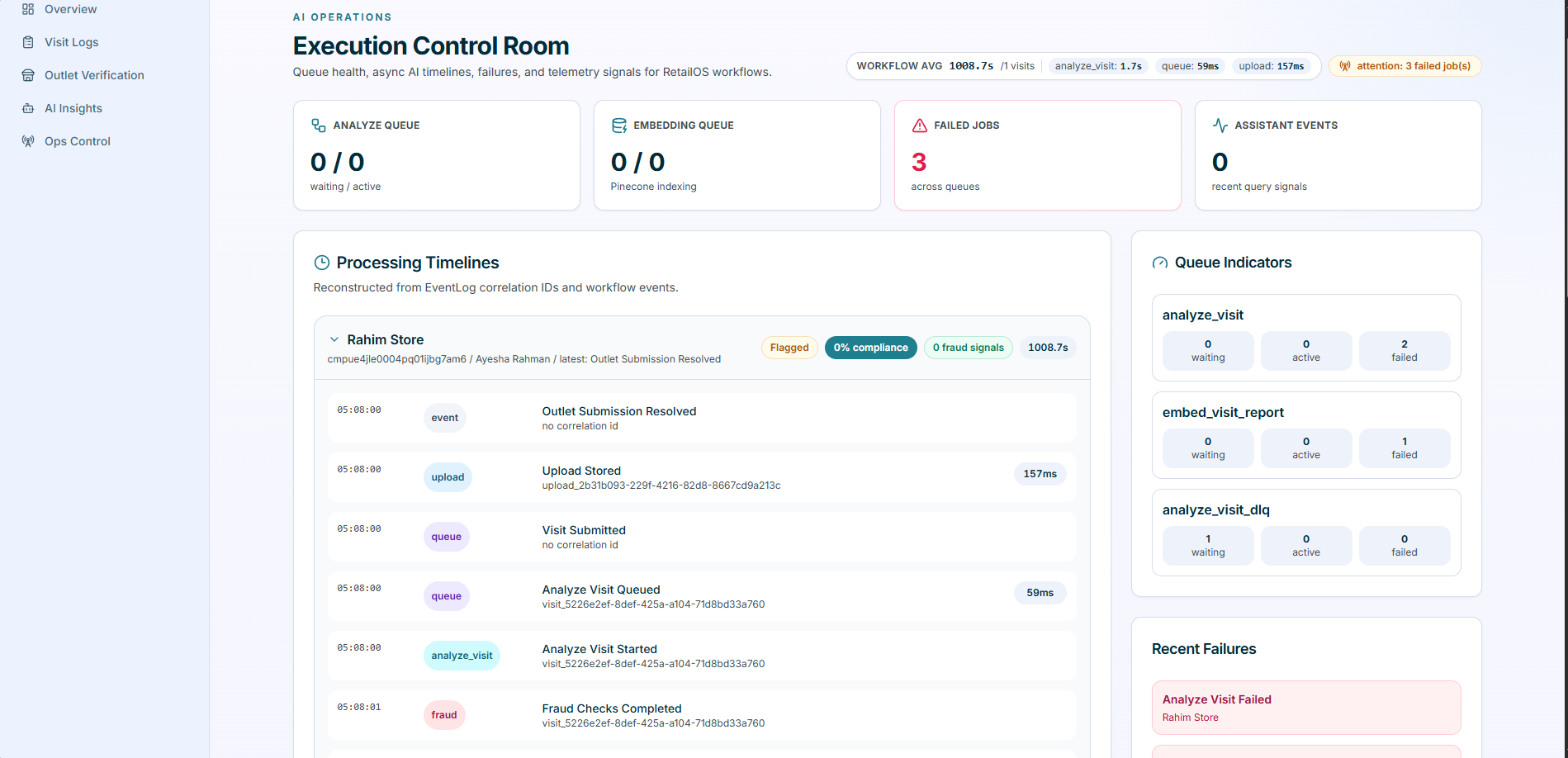
the internal /supervisor/ops page is the demo-safe operational view.
Result: the supervisor ops page shows queue health, failed jobs, assistant events, latency chips, recent failures, and collapsible per-visit processing timelines reconstructed from correlation IDs.
Problem: a sprint demo can work and still be risky: local file uploads, exposed AI service endpoints, unbounded assistant usage, weak recovery paths, and no clean story for serverless deployment.
Implementation: after the demo, I closed the P0/P1 gaps: MinIO/S3 pre-signed uploads, AI service API keys, Redis-backed rate limits, split Prisma pooled/direct DB URLs, admin-only DLQ replay, embedding DLQs, actor metadata on EventLog records, and operational archive tooling.
Why it matters: these are not flashy UI features, but they are the engineering details that turn "it works on my laptop" into "this could survive a pilot."
Runtime Pipeline
sequenceDiagram
autonumber
actor Rep
participant Web as Next.js API
participant DB as PostgreSQL
participant Queue as BullMQ
participant Worker
participant AI as FastAPI AI Service
participant Vec as Pinecone
actor Sup as Supervisor
Rep->>Web: Submit outlet, GPS, notes, image
Web->>DB: Persist visit and upload metadata
Web->>Queue: Enqueue analyze_visit
Web-->>Rep: Return ANALYZING
Queue->>Worker: Process analyze_visit
Worker->>Worker: Fraud checks
Worker->>AI: Analyze shelf image
AI->>AI: YOLO + POSM + compliance
AI-->>Worker: Detections, score, summary
Worker->>DB: Save AIResult, FraudSignal, VisitReport, EventLog
Worker->>Queue: Enqueue embed_visit_report
Worker->>Vec: Upsert visit-report vector
Sup->>Web: Review dashboard, visit detail, assistant, ops timeline
What I Would Defend In A Code Review
Use queues for AI
The rep should not pay the latency cost of YOLO, OpenAI, Pinecone, or WhatsApp. Durable jobs also give retries, DLQs, and measurable backlog.
Keep scoring deterministic
LLMs can describe shelf quality, but supervisors need consistent compliance scores with visible reasons. Rules make the score auditable.
Use exact context for operational RAG
Vectors are useful for similarity and trends. They should not be the source of truth for lists, counts, fraud, compliance, or missing POSM.
Do not hard-delete outlet duplicates
Retail identity changes over time. Merge should preserve history, aliases, reports, and vectors instead of throwing data away.
Representative Code Paths
If I were reviewing this project with an engineer, these are the files I would start with. They show the architecture more clearly than a screenshot can.
worker/src/jobs/analyzeVisit.ts- full async analysis lifecycleworker/src/services/fraud.ts- fraud signal generation and thresholdsai_service/app/main.py- AI service API surface and protected endpointsai_service/app/compliance.py- deterministic compliance scoringlib/outlets.ts- outlet matching, aliases, and merge semanticslib/assistant.ts- exact context builder for RAG answersapp/api/ops/route.ts- queue health and timeline aggregationlib/storage.ts- local/S3-compatible upload abstraction
Tradeoffs And Honest Limits
The system is intentionally local-first for demo reliability, not cloud-deployed yet. YOLO accuracy depends on the small training dataset, so OpenAI is used for POSM and shelf-quality reasoning rather than pretending YOLO can solve classes it never learned. Blur detection was deliberately skipped because it would punish low-end phones and casual hand movement without a more careful image-quality pipeline.
The next production steps would be managed cloud infrastructure, edge/WAF rate limits, scheduled retention jobs, image compression/thumbnails, stronger territory-level authorization, and a proper CI/CD path. The current architecture isolates those changes: storage, AI inference, queueing, and observability are already behind explicit boundaries.
What This Demonstrates
RetailOS Lite is the project where I most clearly demonstrated the kind of engineering I want to keep doing: moving quickly without making a toy, using AI as a system component instead of a buzzword, and caring about the operational details that make software trustworthy after the demo ends.